Releasing public datasets¶
Many social media platforms place limitations on sharing of data collected from their APIs. One common approach for sharing data, in particular for Twitter, is to only share the identifiers of the social media items. Someone can then recreate the dataset be retrieving the items from the API based on the identifiers. For Twitter, the process of extracting tweet ids is often called “dehydrating” and retrieving the full tweet is called “hydrating.”
Note that retrieving the entire original dataset may not be possible, as the social media platform may opt to not provide social media items that have been deleted or are no longer public.
This example shows the steps for releasing the Women’s March dataset to Dataverse. The Women’s March dataset was created by GWU and published on the Harvard Dataverse. These instructions can be adapted for publishing your own collections to the dataset repository of your choice.
Note that the Women’s March dataset is a single (SFM) collection. For an example of publishing multiple collections to a single dataset, see the 2016 United States Presidential Election dataset.
Exporting collection data¶
Access the server where your target collection is located and instantiate a processing container. (See Command-line exporting/processing):
ssh sfmserver.org cd /opt/sfm docker-compose run --rm processing /bin/bash
Replace
sfmserver.orgwith the address of the SFM server that you want export data from.Find a list of WARC files where the data of your target collection are stored, and create a list of WARC files (source.lst) and a list of destination text files. (dest.lst):
find_warcs.py 0110497 | tr ' ' '\n' > source.lst cat source.lst | xargs basename -a | sed 's/.warc.gz/.txt/' > dest.lst
Replace
0110497with the first few characters of the collection id that you want to export. The collection id is available on the collection detail page in SFM UI. (See the picture below.)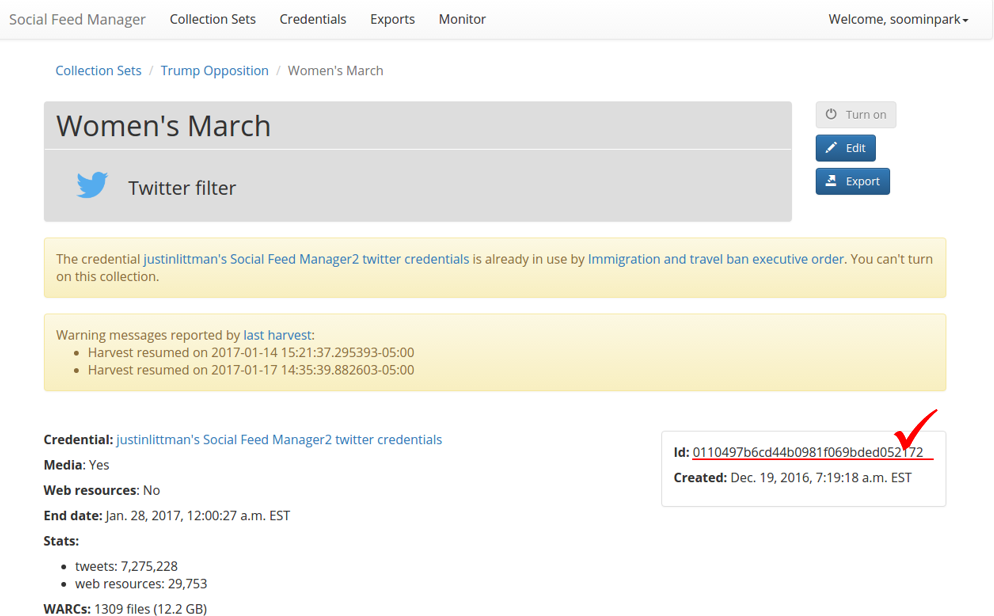
Write the tweet ids to the destination text files:
time parallel –j 3 -a source.lst -a dest.lst --xapply "twitter_stream_warc_iter.py {1} | jq –r ‘.id_str’ > {2}"This command executes a Twitter Stream WARC iterator to extract the tweets from the WARC files and jq to extract the tweet ids. This shows using twitter_stream_warc_iter.py for a Twitter stream collection. For a Twitter REST collection, use twitter_rest_warc_iter.py.
Parallel is used to perform this process in parallel (using multiple processors), using WARC files from source.lst and text files from dest.lst. -j 3 limits parallel to 3 processors. Make sure to select an appropriate number for your server.
An alternative to steps 1 and 2 is to use a sync script to write tweet id text files and tweet JSON files in one step. (See Command-line exporting/processing)
Combine multiple files into large files:
The previous command creates a single text file containing tweet ids for each WARC file. To combine the tweets into a single file:
cat *.txt > womensmarch.txt
- Recommendation: If there are a large number of tweet ids in a file, split into multiple, smaller files. (We limit to 50 million tweet ids per file.)
Create a README file that contains information on each collection (management command for sfm ui):
Exit from the processing container, and connect to the UI container and execute the exportreadme management command to create a README file for the dataset:
exit docker-compose exec ui /bin/bash -c "/opt/sfm-ui/sfm/manage.py exportreadme 0110497 > /sfm-processing/womensmarch-README.txt"
Copy the files from the server to your local hard drive:
Exit from the SFM server with
exitcommand, move to a location in your local hard drive where you want to store the data, and run the command below:exit scp -p username@sfmserver.org:/sfm-processing/womensmarch*.txt .
Replace
usernameandsfmserver.orgwith your user ID and the address of the SFM server, respectively.
Publishing collection data on Dataverse¶
For this example, we will be adding the collection to the GW Libraries Dataverse on the Harvard Dataverse instance.
Go to the GW Libraries Dataverse and log in.
- Note: You should be a Curator for the dataverse to be able to upload data.
Open the New Dataset page:
Click ‘Add Data > New Dataset’.
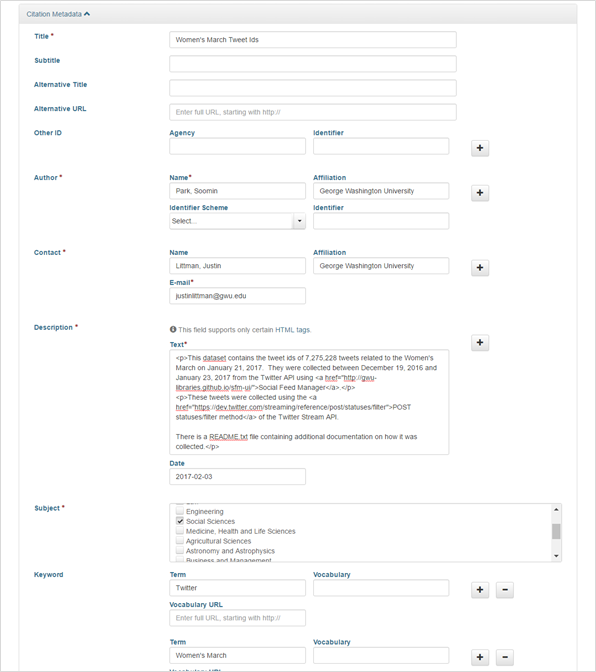
Fill the metadata with proper information (title, author, contact, description, subject, keyword):
Make sure you input the right number of tweets collected and appropriate dates in the description.
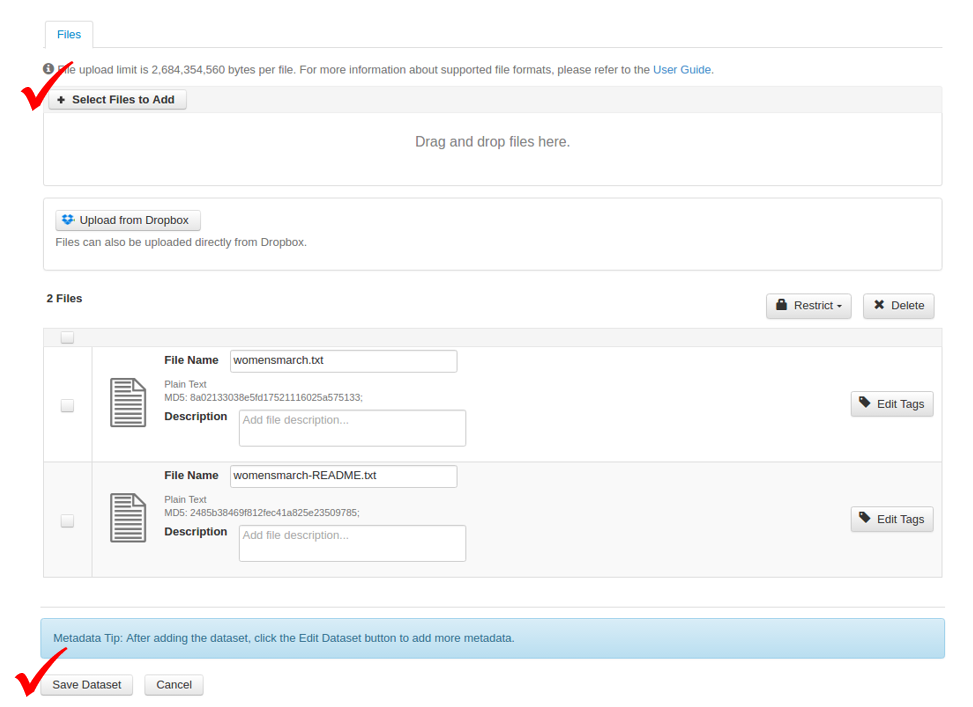
Upload the files (both data and README files) and save the dataset:
- Note: The dataset will be saved as a draft.
Publish the dataset:
Go to the page of the draft that was just saved, and click ‘Publish’ button.
Adding link to Dataverse dataset¶
Once you have published your collection data on Dataverse, you can add to it from SFM. This will allow other SFM users to find the public version of your collection.
- Go to the collection page for your collection in SFM and click Edit.
- Add the Dataverse link to in the “Public Link” field and click Save.